Un groupe de chercheurs s’est servi de l’immense réservoir de livres que Google a numérisés jusqu’ici — 15 millions de titres, dans 7 langues. Ils en ont utilisé le tiers —la portion, disent-ils, offrant la meilleure qualité de numérisation — pour créer leur base de données. Et ils ont commencé leurs découvertes... par mots-clefs.
Abonnez-vous à notre infolettre!
Pour ne rien rater de l'actualité scientifique et tout savoir sur nos efforts pour lutter contre les fausses nouvelles et la désinformation!
On y apprend par exemple que les acteurs anglophones (les deux tiers des livres numérisés sont en anglais) atteignent le sommet de leur célébrité vers l’âge de 30 ans, contre 40 ans pour les écrivains. Que l’artiste juif Marc Chagall est pratiquement disparu des livres en allemand parus sous le régime nazi, alors qu’il restait populaire dans la littérature anglophone. Et on apprend aussi qu’en anglais, seulement la moitié des mots en usage dans les livres — les livres numérisés, du moins — sont recensés dans les dictionnaires.
Ces constats et d’autres font partie de l’article paru dans l'édition en ligne de la revue Science , et signé à la fois par des gens de l’Université Harvard et de Google Books.
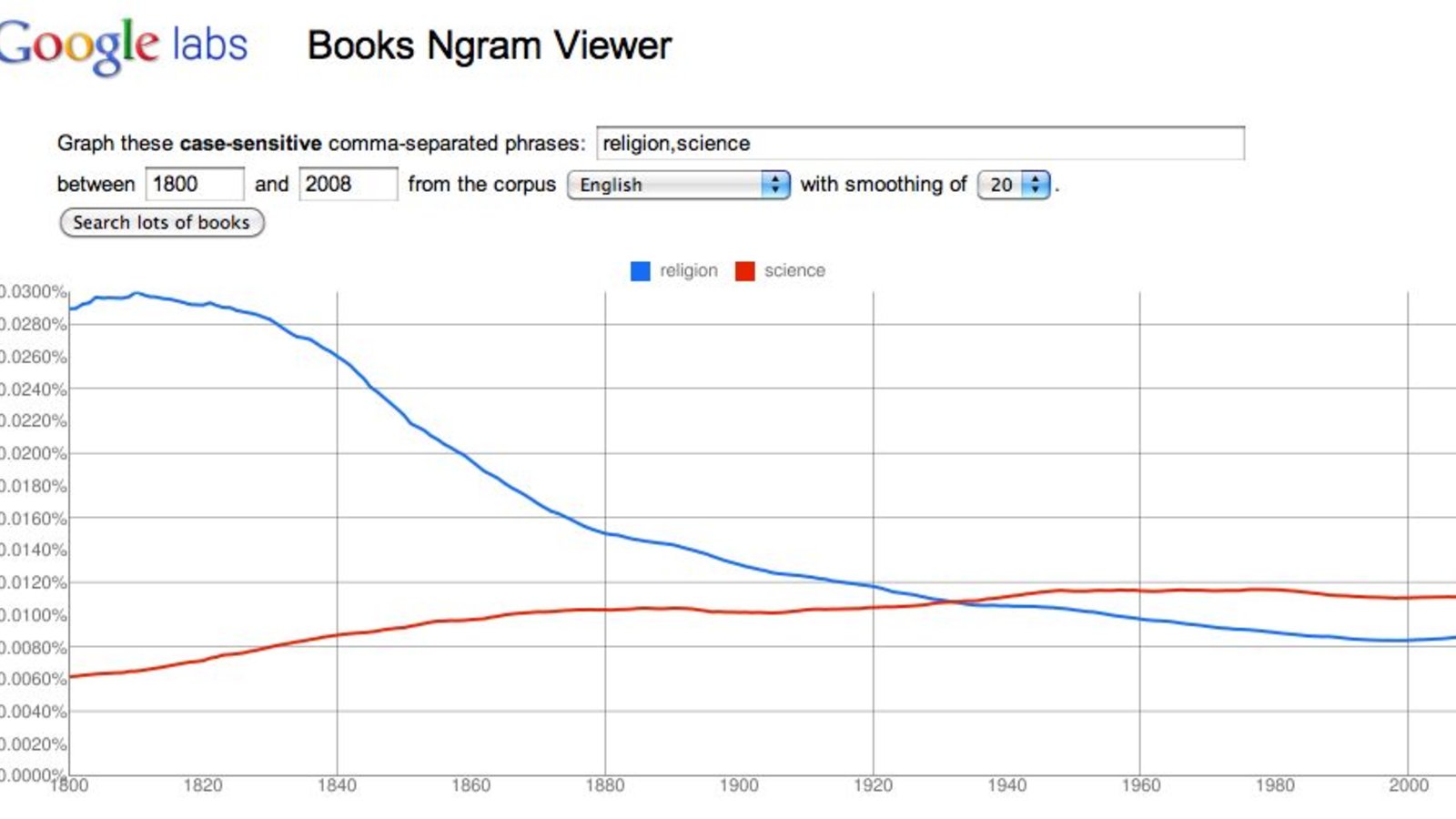
Une partie de la base de données, couvrant la période de 1800 à aujourd’hui, est accessible à tous : n’importe qui peut donc s’amuser à faire ses propres recherches. Par exemple, mettre dans le même graphique « religion » et « science » donne une image tout de suite révélatrice (photo).
Nous avons aussi pu constater que, comme prévu, le mot « vulgarisation », en français, connaît une progression presque constante depuis 1840. En revanche, cette progression diminue de manière intriguante pendant les années 1960 et 1970, et depuis 1985.
Le New Scientist a pour sa part découvert un bogue : le mot « nanotechnologie » semble faire une première apparition en... 1899! Tout comme iPod, et Internet, et polymérase. Vérification faite, il s’agit plutôt d’une erreur du système de reconnaissance de caractères.
En français par contre, « nanotechnologie » apparaît pour la première fois en 1948, dans le Bulletin de la Société française de microscopie théorique et appliquée.
Mais est-on aussi sûr qu’il s’agit d’un nouveau champ de recherche — la « culturomique » — comme le prétendent ces chercheurs? Après tout, il y a longtemps que des chercheurs en linguistique ou en histoire effectuent de telles recherches quantitatives — nombre de mots, de phrases, occurrences d’un nom propre, etc.
On remarque d’ailleurs que dans cette équipe de Harvard et de Google Books, il y a des biologistes (dont le chercheur principal, Jean-Baptiste Michel, de Harvard), un psychologue spécialiste de la cognition du langage (Steven Pinker), des informaticiens, un récent doctorant en mathématiques et génie biologique (Erez Lieberman Aiden, à qui on doit le mot culturomique), mais aucun historien, ni chercheurs en sciences sociales (sauf un lexicographe, ou spécialiste de la classification des mots).
Le simple fait que le texte ait été soumis à Science, relève le linguiste Geoffrey Nunberg dans la Chronicle of Higher Education, « suggère que les auteurs sont plus intéressés à gagner l’oreille de leurs collègues scientifiques ».
Pour l’instant, c’est un nouvel outil qui reste encore à être expérimenté, spécialement par les premiers intéressés, les gens en histoire et en linguistique. Et peut-être plus spécifiquement encore, les historiens de la linguistique, qui s’en donneront à coeur joie.