

Des algorithmes d’intelligence artificielle peuvent-ils être sexistes et racistes? Le Détecteur de rumeurs a identifié plusieurs exemples qui favorisent effectivement la discrimination.
Cet article fait partie de la rubrique du Détecteur de rumeurs, cliquez ici pour les autres textes.
À lire également
Des exemples
En 2014, Amazon a mis au point un logiciel pour analyser les CV des candidats à des postes dans leur entreprise. Le logiciel avait été entraîné grâce à une banque de données contenant le profil des employés embauchés ou promus sur une période de 10 ans. En 2015, l’entreprise a toutefois découvert que le système avait une nette préférence pour les candidats masculins.
Une étude réalisée en 2017 par une chercheuse de l’Université de Washington a pour sa part montré que le logiciel de reconnaissance vocale de Google était moins efficace pour traiter les voix féminines. Selon l’auteure, cette différence pourrait s’expliquer par le fait que le logiciel serait moins performant pour analyser des voix aiguës.
Abonnez-vous à notre infolettre!
Pour ne rien rater de l'actualité scientifique et tout savoir sur nos efforts pour lutter contre les fausses nouvelles et la désinformation!
En 2018, des chercheurs associés à Microsoft ont testé des applications utilisées pour analyser des images et déterminer le sexe de la personne. Ils ont remarqué que ces applications avaient un taux d’erreur très bas (0,8 %) pour identifier les hommes blancs, mais de 34,7 % pour les femmes noires.
Enfin, certains algorithmes d’intelligence artificielle développés pour prédire le risque de récidive de jeunes contrevenants présentent des biais racistes, selon une étude réalisée en 2019 en Espagne. Les chercheurs ont observé qu’un homme d’origine étrangère avait deux fois plus de chances d’être incorrectement classé comme à haut risque de récidive qu’un homme d’origine espagnole.
Des familles de mots stéréotypées
Ces exemples et bien d’autres sont connus. Et la raison est elle aussi connue : la grande majorité des logiciels d’intelligence artificielle utilisent l’approche de l’apprentissage machine.
Il s’agit de permettre à l’ordinateur de trouver comment exécuter une tâche le plus efficacement possible, en lui fournissant une énorme quantité de données pour l’entraîner. Le problème est que, dans cette immense quantité de données, peuvent se glisser des biais, des stéréotypes, des préjugés.
Une branche particulière de l’apprentissage machine s’appelle le traitement du langage naturel. Cette technologie repose entre autres sur l’utilisation des statistiques pour prédire le prochain mot d’une phrase en se basant sur les mots précédents. C’est cette branche qui est derrière le succès des robots comme ChatGPT depuis l’an dernier : ils prédisent des séquences de mots à une vitesse phénoménale.
Pour ce faire, il faut d’abord convertir les mots en nombre, grâce à une approche appelée la vectorisation de mots. Cela permet de regrouper les termes avec un sens similaire.
Or, dès 2016, une étude américaine avait montré que ces ensembles de mots contenaient des biais qui reflétaient les stéréotypes présents dans la société: la femme « ménagère » (homemaker) et l’homme informaticien, par exemple. Une autre étude réalisée en 2017 a par ailleurs conclu que la vectorisation de mots associe généralement les femmes à des mots concernant la famille et les arts alors qu’elle associe les hommes à des mots en lien avec la carrière, la science et la technologie.
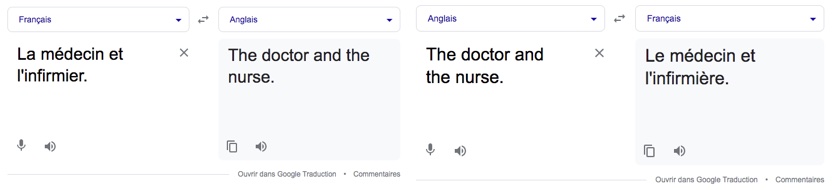
On peut observer soi-même ce phénomène en utilisant Google Translate. Si on demande à l’algorithme de traduire « la médecin et l’infirmier » en anglais, on obtient « the doctor and the nurse », des mots non-genrés. Cependant, si on veut faire la traduction inverse, on obtient plutôt « le médecin et l’infirmière ».
Des données biaisées au départ?
Dans un article récent discutant des enjeux éthiques de l’intelligence artificielle, l’International Peace Institute (IPI) s’est inquiété de cette question des biais et stéréotypes. Ceux-ci, rappelle le texte, peuvent survenir à différentes étapes de la création des applications: lors du développement de l’algorithme, lors de son entraînement grâce à des banques de données, ou à l’étape de la prise de décision par l’IA.
Mais c’est la base de données utilisée pour entraîner l’ordinateur qui est l’une des plus importantes sources de biais. Si elle contient elle-même des biais, ceux-ci seront intégrés à l’algorithme. Par exemple, dans le cas du logiciel d’Amazon, le biais négatif envers les femmes reflétait les tendances d’embauche de la compagnie dans les années précédentes. Le logiciel avait en effet été entraîné avec des profils d’employés presque exclusivement masculins.
Dans le cas de l’étude de Microsoft sur la reconnaissance des visages par l’IA, les chercheurs ont fini par remarquer que les bases de données utilisées pour entraîner les algorithmes étaient composées à près de 80 % de visages à la peau claire. Des chercheurs britanniques sont arrivés à une conclusion similaire en 2021 quand ils ont analysé des algorithmes développés pour détecter les cancers de la peau : les peaux foncées étaient substantiellement sous-représentées dans les banques de données qui servent à entraîner ces algorithmes.
Peu de diversité chez les programmeurs
La personne qui conçoit l’algorithme peut aussi lui transférer, consciemment ou non, ses propres biais. Le programmeur peut en effet mettre en place des règles qui contiennent des biais implicites, remarque Brian Uzzi, professeur à l’Université Northwestern dans un article qui s’intéresse aux moyens pour réduire les biais dans l’IA.
Ce phénomène est illustré par une étude réalisée en 2020 par des chercheurs américains. Ceux-ci ont utilisé différents logiciels de catégorisation d’images pour analyser des photographies des élus du Congrès américain. Ces algorithmes avaient été entraînés avec des banques d’images, elles-mêmes catégorisées par des programmeurs à partir d’un ensemble de mots datant de 1980. Résultat : les étiquettes attribuées aux images de femmes faisaient généralement référence à leur apparence, alors que celles attribuées aux hommes étaient en lien avec leur occupation.
Piste de solution
Une des solutions pour diminuer les biais de l’intelligence artificielle semble donc être de diversifier le bassin de programmeurs. De fait, les femmes sont sous-représentées dans les domaines de la programmation, des technologies de l’information, du génie, des mathématiques et de la physique. Par exemple, une enquête réalisée en 2018 par le magazine Wired avait conclu que seulement 12 % des chercheurs de pointe en apprentissage machine étaient des femmes. En 2022, les femmes occupaient seulement 25,8 % des postes techniques chez Meta et les personnes noires, seulement 2,4 %.
Verdict
Il est presque inévitable que les logiciels d’intelligence artificielle présentent des biais sexistes ou racistes. À cause du mode même de fonctionnement de l’IA, qui consiste à la nourrir d’immenses bases de données, ces biais reflètent ceux qui, conscients ou inconscients, existent dans notre société, se retrouvent donc dans ces bases de données, et chez les programmeurs.
Photo: Suriya Phosri | Dreamstime.com

Vous aimerez aussi
-
 Prédire les inondations grâce à l’IA?Vendredi 22 mars 2024
Prédire les inondations grâce à l’IA?Vendredi 22 mars 2024 -
 Le Web a 35 ans: peut-il revenir à ce qu’il devait être?Vendredi 15 mars 2024
Le Web a 35 ans: peut-il revenir à ce qu’il devait être?Vendredi 15 mars 2024 -
 L’IA pour remplacer les défunts?Mardi 27 février 2024
L’IA pour remplacer les défunts?Mardi 27 février 2024 -
 Se rappeler que l’IA n’est pas humaineJeudi 22 février 2024
Se rappeler que l’IA n’est pas humaineJeudi 22 février 2024 -
 Travail : les ressources humaines dans la mire de l’IAJeudi 18 janvier 2024
Travail : les ressources humaines dans la mire de l’IAJeudi 18 janvier 2024 -
 L’IA peut aussi fabriquer des données trompeusesMardi 28 novembre 2023
L’IA peut aussi fabriquer des données trompeusesMardi 28 novembre 2023