

ChatGPT et les autres formulent parfois des réponses étranges lorsqu’ils sont confrontés à des requêtes contenant des mots négatifs. Le Détecteur de rumeurs a voulu comprendre pourquoi la négation demeure un défi pour l’intelligence artificielle.
Cet article fait partie de la rubrique du Détecteur de rumeurs, cliquez ici pour accéder aux autres textes.
À lire également
Faits à retenir
- L’IA a des difficultés à comprendre le langage humain
- La négation semble être un concept qui continue de lui échapper
- C’est un gros défi avec les images
En 2024, le psychologue américain et expert en IA Gary Marcus résumait sur son blogue personnel les histoires d’utilisateurs qui s’étaient amusés à demander à ChatGPT de créer l’image d’une « pièce vide ne contenant absolument aucun éléphant ». En guise de réponse, le logiciel leur avait fourni plusieurs images… avec un éléphant!
Abonnez-vous à notre infolettre!
Pour ne rien rater de l'actualité scientifique et tout savoir sur nos efforts pour lutter contre les fausses nouvelles et la désinformation!
La même année, lui aussi sur son blogue personnel, Sean Trott, professeur adjoint au département d’informatique de l’Université de Californie à San Diego, racontait comment il avait dû faire plusieurs tentatives pour que ChatGPT réussisse à produire une image d’un robot dans un bureau de scrutin, mais sans drapeau américain.
Les deux experts utilisaient ces exemples pour illustrer les difficultés qu’éprouve l’IA à comprendre le langage humain, mais plus précisément dans ce cas-ci, ses difficultés à comprendre la négation.
La négation: un vieux défi pour l’IA
Les problèmes de l’IA avec la négation ne datent pas d’hier. En 2020, Allyson Ettinger, professeure au département de linguistique de l’Université de Chicago, s’était intéressée à la compréhension des négations d’un grand modèle de langage (LLM) très populaire à l’époque, BERT. Elle lui avait demandé de compléter des phrases comme « Un rouge-gorge est un… » ou « Un rouge-gorge n’est pas un… ». Elle avait alors constaté que le logiciel lui proposait les mêmes mots pour les deux phrases, dont « oiseau » et « rouge-gorge ».
La même année, une équipe de scientifiques du Texas notait que la négation constituait un défi pour les IA qui étaient utilisées en traduction. En effet, les performances de ces logiciels étaient généralement plus basses si la phrase à traduire contenait une négation.
Un défi même avec les images
Du coup, cette difficulté à comprendre les négations dans une requête affecte aussi les modèles qui produisent des images. Par exemple, en 2024, une équipe de chercheurs indiens et britanniques a soumis des requêtes à différents modèles d’IA. Ceux-ci devaient générer « une personne sans lunettes », « un éléphant sans défenses » ou « des fleurs sans couleur bleue ». Autant GPT-4 que Gemini ou Copilot ont eu un très bas taux de succès.
Le Détecteur de rumeurs a procédé à son propre test maison. Nous avons demandé à ChatGPT de produire une carte du monde sans le Canada. Voici ce que nous avons obtenu.
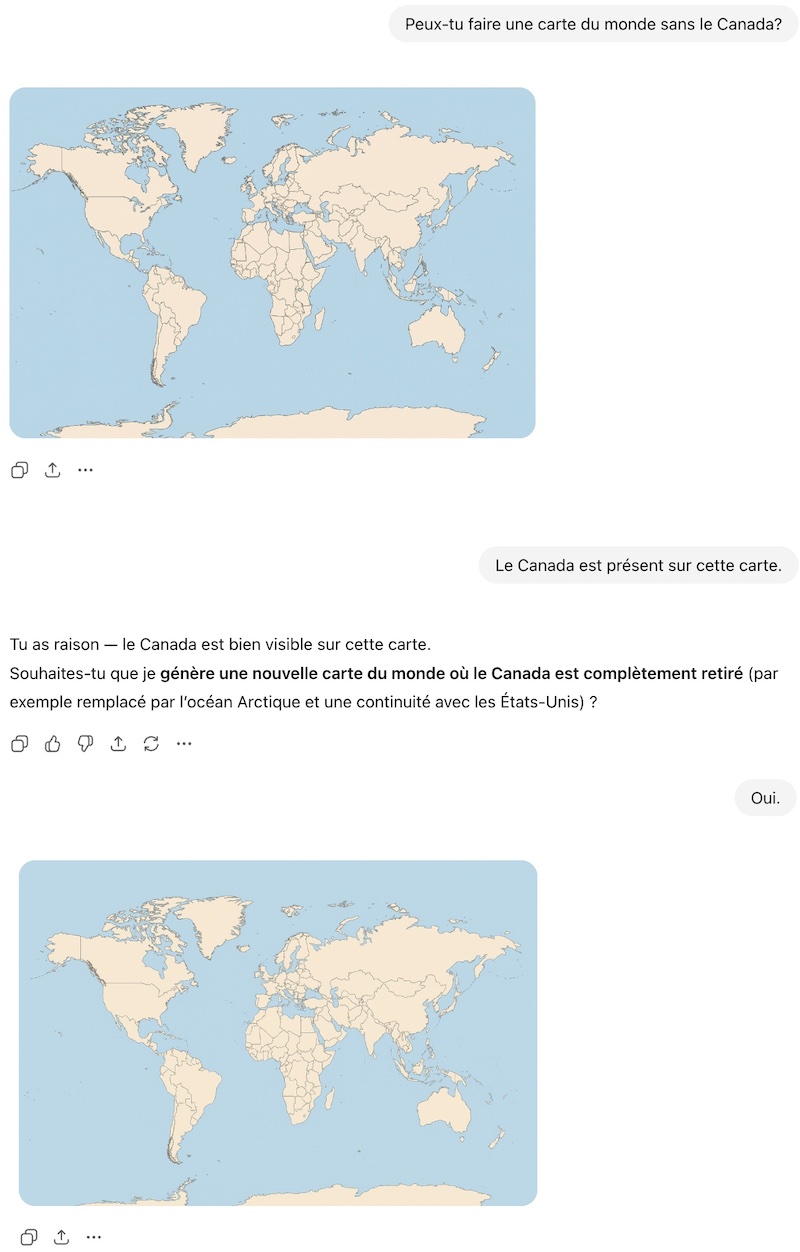
Ignorer la négation
Le défi que représente la négation touche également un autre type d’IA, les modèles vision-langage. Ceux-ci combinent des algorithmes de traitement d’images avec des algorithmes de traitement du langage. Ils sont utilisés, par exemple, pour analyser des images médicales et repérer les anomalies.
En 2025, des chercheurs du MIT ont testé un de ces modèles pour déterminer s’il pouvait traiter les requêtes négatives. Dans une première tâche, le logiciel devait trouver des images qui respectaient certains critères d’inclusion et d’exclusion (par exemple, une image avec un chien, mais pas de gazon). Pour la deuxième tâche, il devait trouver la meilleure description pour une image parmi des phrases contenant des éléments négatifs (par exemple, le sol est visible, mais il n’y a pas de chien).
Les chercheurs ont constaté que le modèle avait de la difficulté à comprendre les négations. Ainsi, dans la deuxième tâche, il choisissait des phrases qui niaient la présence d’objets alors que ceux-ci étaient bien présents dans l’image. En fait, le modèle semblait carrément ignorer les mots qui marquent la négation.
Ce comportement peut être problématique dans le domaine médical. Par exemple, l’absence de certaines caractéristiques sur une radiographie peut mener à un diagnostic complètement différent, soulignaient les auteurs.
Pourquoi autant de mal avec la négation?
Mais pourquoi les logiciels d’IA ont-ils autant de difficultés à traiter les requêtes négatives? Une des explications vient du mode de fonctionnement des logiciels comme ChatGPT, appelés grands modèles de langage (LLM).
Pour prédire des séquences de mots, les LLM doivent d’abord convertir les mots en nombres, grâce à une approche appelée la vectorisation de mots. Ils peuvent ainsi regrouper les termes qui ont un sens similaire. La négation est toutefois un processus linguistique qui introduit un niveau de complexité plus élevé : le sens d’une phrase est inversé. En 2025, Saurabh Sarkar, fondateur d’une compagnie qui développe des systèmes d’IA, expliquait que la vectorisation ne permet pas, d’un point de vue mathématique, d’inverser les associations entre les mots.
De plus, en entrevue pour le magazine The New Scientist en 2025, Karin Verspoor, de l’Institut royal de technologie de Melbourne, soulignait que les mots comme « ne… pas » ou « sans » peuvent se retrouver dans des contextes très variés et que cela rend le travail plus difficile pour les LLM, parce que ceux-ci se fient d’abord au contexte pour saisir le sens d’une phrase.
Un autre problème est qu’on retrouve plusieurs exemples de phrases affirmatives comme « ceci est un chat » dans les grandes banques de données qui servent à « entraîner » les LLM, mais peu de phrases du genre « ceci n’est pas un chat », comme le notait également Saurabh Sarkar. Cette opinion est partagée par les chercheurs du MIT qui soulignaient que les données d’entraînement des modèles vision-langage contiennent très peu d’images avec des descriptions négatives.
Enfin, il y a la grande difficulté, pour un LLM, de visualiser ce qui n’existe pas. En 2025, Senjuti Dutta, une chercheuse en intelligence artificielle qui s’intéresse aux LLM, écrivait que les modèles peuvent réussir à produire une image d’une personne sans lunettes parce qu’il existe plusieurs images de ce genre dans leurs données d’entraînement. En comparaison, trouver l’image d’un avion sans ailes est plus difficile. D’ailleurs, lorsque nous avons demandé à ChatGPT pourquoi il ne parvenait pas à produire une carte du monde sans le Canada, il a donné l’explication suivante.

Des modèles qui s’améliorent
Pour améliorer la capacité des LLM à traiter les négations, des experts ont donc proposé de les entraîner avec des banques de données contenant davantage d’expressions négatives, soulignaient déjà en 2023 des chercheurs d’Oxford.
Ceux-ci ont d’ailleurs évalué la fiabilité de ChatGPT dans différentes situations, dont la compréhension de la négation. Ils ont remarqué que celui-ci s’était amélioré par rapport aux performances des anciens modèles comme BERT. Selon les auteurs, l’incorporation d’étapes de rétroaction humaine aurait joué un rôle crucial pour permettre à certains LLM de mieux comprendre le sens des négations.
Toutefois, certains experts en IA ont aussi avancé depuis deux ans que la capacité des LLM à s’améliorer en général —par exemple, quand il s’agit d’éviter de dire des faussetés— approchait peut-être de ses limites, en raison à la fois de leur « entraînement » et du fait que les compagnies hésitent à les programmer pour admettre que la réponse qu’ils donnent est incertaine.
Verdict
Comprendre les phrases négatives demeure un défi pour les logiciels d’intelligence artificielle, en raison de leur mode de fonctionnement. Ces IA se sont récemment améliorées par rapport aux modèles précédents, mais l'existence d'une limite à leurs capacités demeure possible.

Vous aimerez aussi
-
 Les dispositifs d’aide à la conduite réduisent les accidents? VraiMardi 14 juillet 2026
Les dispositifs d’aide à la conduite réduisent les accidents? VraiMardi 14 juillet 2026 -
 L’IA permet aux entreprises d’économiser? Pas pour le momentMardi 30 juin 2026
L’IA permet aux entreprises d’économiser? Pas pour le momentMardi 30 juin 2026 -
 Trop d’IA rend-il moins bon à détecter les fausses nouvelles?Jeudi 25 juin 2026
Trop d’IA rend-il moins bon à détecter les fausses nouvelles?Jeudi 25 juin 2026 -
 Centres de données: 3% de l’électricité mondiale en 2030Lundi 8 juin 2026
Centres de données: 3% de l’électricité mondiale en 2030Lundi 8 juin 2026 -
 Valider des résultats scientifiques: avantage aux humainsVendredi 5 juin 2026
Valider des résultats scientifiques: avantage aux humainsVendredi 5 juin 2026 -
 Violences contre les femmes encouragées par l’IALundi 1 juin 2026
Violences contre les femmes encouragées par l’IALundi 1 juin 2026

Les plus populaires



