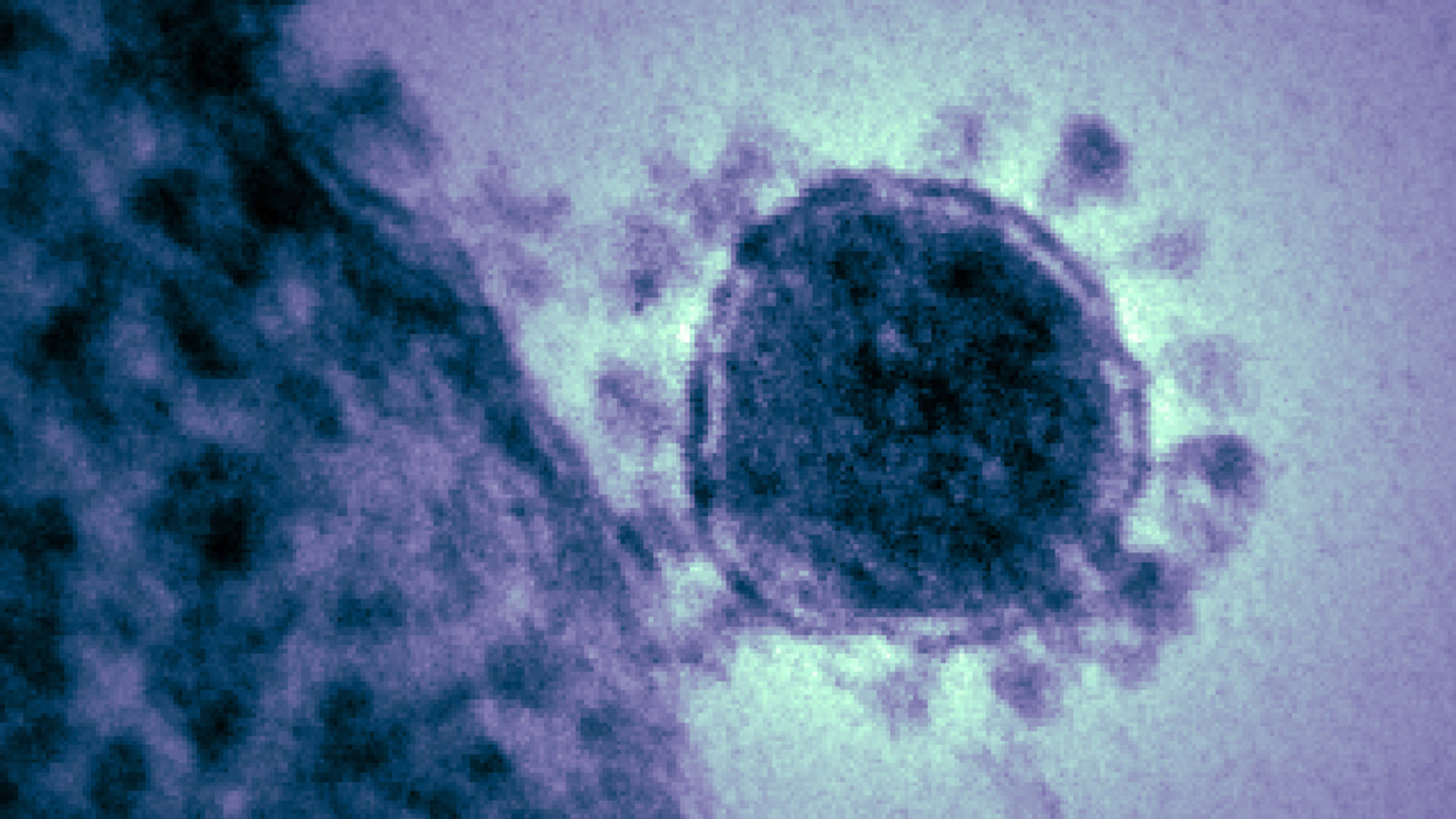
Il y a un an, le 11 janvier 2020, était publié le tout premier décodage du génome d’un virus qui commençait à susciter beaucoup d’inquiétudes —un décodage qui confirmait qu’on avait des raisons de s’inquiéter.
Déjà, le 5 janvier, les premières données avaient révélé que la « pneumonie virale » qui sévissait à Wuhan était causée par un coronavirus. Comme le rappelaient en fin de semaine Yong-Zhen Zhang, du Centre chinois de contrôle des maladies, et Eddie Holmes, de l’Université de Sydney, Australie, tous deux avaient d'abord pensé que le SRAS —le syndrome respiratoire aigu sévère— qui avait fait 800 morts en 2002 et 2003, était de retour.
Mais les différences au sein du génome de cet intrus tendaient plutôt à conclure qu’il s’agissait d’un nouveau coronavirus —soit une épidémie contre laquelle on n’avait aucune parade. Des chercheurs chinois ont publié un avertissement à ce sujet cette semaine-là —quoique en prévenant, face à des autorités chinoises qui ne favorisaient pas la transparence, qu’on n’était pas encore sûr du degré de dangerosité du virus. Quelques jours plus tard, le 11 janvier, Zhang et Holmes mettaient en ligne la séquence complète des gènes d’un échantillon de ce qui allait s'appeler le SRAS-CoV-2, en accès libre pour les chercheurs du monde entier.
Abonnez-vous à notre infolettre!
Pour ne rien rater de l'actualité scientifique et tout savoir sur nos efforts pour lutter contre les fausses nouvelles et la désinformation!
Aujourd’hui, près de 4000 génomes de ce virus à travers le monde ont été publiés, ce qui permet de suivre à la trace ses mutations d’une région à l’autre. Cette première publication, le 11 janvier, est souvent saluée par les experts comme le point de départ d'une frénésie de recherches et de publications pour comprendre les mécanismes par lesquels ce virus s’infiltre dans nos cellules —et les mécanismes d'un éventuel traitement.

Vous aimerez aussi
-
 L’écureuil, cet archivisteLundi 15 juin 2026
L’écureuil, cet archivisteLundi 15 juin 2026 -
 L’homme des glaces et son champignon des glacesJeudi 4 juin 2026
L’homme des glaces et son champignon des glacesJeudi 4 juin 2026 -
 Avoir des chromosomes en double (ou plus)Mardi 19 mai 2026
Avoir des chromosomes en double (ou plus)Mardi 19 mai 2026 -
 Cet Homo erectus a-t-il laissé une trace en nous?Jeudi 14 mai 2026
Cet Homo erectus a-t-il laissé une trace en nous?Jeudi 14 mai 2026 -
 La génétique des invasions barbaresJeudi 30 avril 2026
La génétique des invasions barbaresJeudi 30 avril 2026 -
 L’ivermectine peut guérir la COVID, le cancer, l’Alzheimer et le Parkinson ? FauxMercredi 29 avril 2026
L’ivermectine peut guérir la COVID, le cancer, l’Alzheimer et le Parkinson ? FauxMercredi 29 avril 2026

Les plus populaires